Kubernetes Servie 原理及使用说明
官方文档:https://kubernetes.io/zh/docs/concepts/services-networking/service/
前言: Kubernetes Pod 是有生命周期的,每个 Pod 都有自己的IP的地址,然而 Pod 一旦被销毁生命周期就会结束,然后被控制器重新拉起,所以它的 IP 地址是动态不稳定的,这个会导致一个问题:在 Kubernetes 集群中,如果一组 Pod(称其为 backend)为其它 Pod(称其为 frontend ) 提供服务,那么这些 frontend 该如何发现,并把流量转发连接到这组 Pod 中呢?
Service 简介
Service 概念定义
Kubernetes Service 定义了这样一种抽象:Service 是一种可以访问 Pod 逻辑分组的策略,Service 通常是通过 Label Selector 访问 Pod 组。
Service 能够提供负载均衡的能力,但是在使用上有以下限制:Service 只提供四层负载均衡能力,没有 7 层功能 ,生产中需要经常使用更多的匹配规则来转发请求,比如HTTP,这点上 4 层负载均衡是不支持的 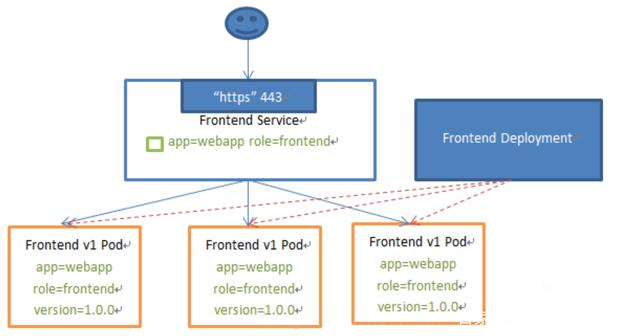
Service 类型
ClusterIP
通过集群的内部 IP 暴露服务,选择该值时服务只能在集群内部访问。这也是默认的 ServiceType 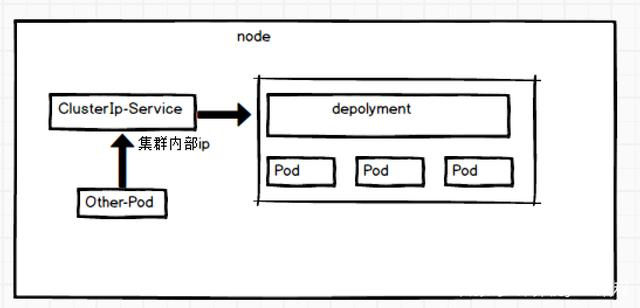
NodePort
通过每个节点上的 IP 和静态端口(NodePort)暴露服务。NodePort 服务会路由到自动创建的 ClusterIP 服务。通过请求<节点 IP>:<节点端口>,可以从集群的外部访问一个 NodePort服务 说明:NodePort 节点端口,默认为 30000-32767 范围 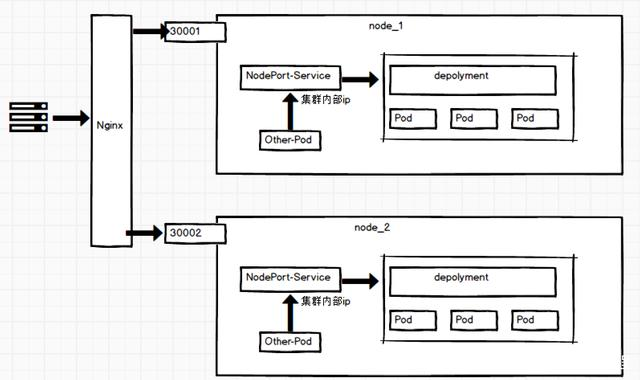
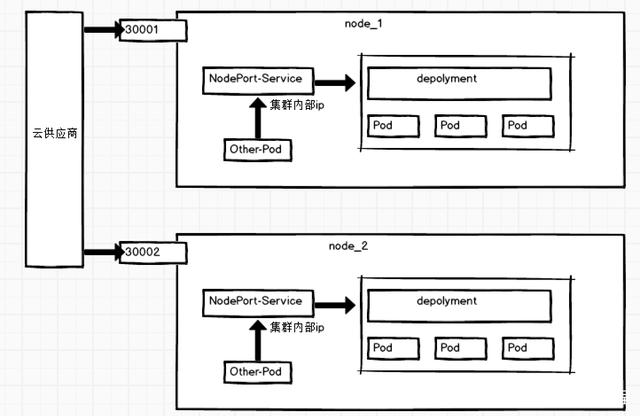
LoadBalance
使用云厂商提供的负载均衡产品向外部暴露服务。外部负载均衡器可以将流量路由到自动创建的 NodePort 服务和ClusterIP 服务上
ExternalName
把集群外部的服务引入到集群内部来,在集群内部直接使用。通过返回CNAME 和对应值,可以将服务映射到 ExternalName 字段的内容(例:test.qiqios.cn)。无需创建任何类型代理 说明:需要使用 kube-dns 1.7 及以上版本或者 CoreDNS 0.0.8 及以上版本才能使用 ExternalName 类型。
Service 基础导论
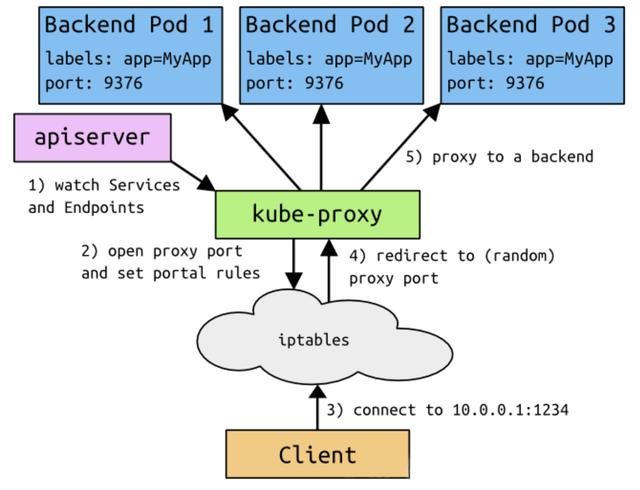
- 客户端访问节点时通过 iptables 实现的
- iptables 规则是通过 kube-proxy 组件写入的
- apiserver 通过监控 kube-proxy 去进行对服务和 端点 的监控
- kube-proxy 通过 pod 的标签 labels 去判断这个端点信息是否写入到 Endpoints 中
Service 代理
VIP 和 Service 代理
在 Kubernetes 集群中,每个 Node 运行一个 kube-proxy 进程。kube-proxy 负责为 Service 实现了一种 VIP(虚拟IP)的形式,而不是 ExternalName 的形式,在 Kubernetes v1.0 版本,代理完全在 userspace,在 Kubernetes v1.1 起,代理默认就是 iptables,在 1.14 版本开始默认使用 ipvs 代理。
在 Kubernetes v1.0 版本,Service 是 4 层(TCP/UDP over IP)概念。在 Kubernetes v1.1版本中,新增了 Ingress API ,用来表示 7 层(HTTP)服务,为何不使用 round-robin DNS 呢
因为DNS 会在很多的客户端里进行缓存,很多服务在访问 DNS 进行域名解析完成,得到地址后不会对DNS 的解析地址进行清除缓存的操作,所以一旦获取到它的地址信息后,不管访问几次还是原来缓存下来的地址信息,导致负载均衡失效。
代理模式分类
userspace 代理模式


这种模式,kube-proxy 会监视 Kubernetes 控制平面对 Service 对象和 Endpoints 对象的添加和移除操作。 对每个 Service,它会在本地 Node 上打开一个端口(随机选择)。 任何连接到 “代理端口” 的请求,都会被代理到 Service 的后端 Pods 中的某个上面(如 Endpoints 所报告的一样)。 使用哪个后端 Pod,是 kube-proxy 基于 SessionAffinity 来确定的。
最后,它配置 iptables 规则,捕获到达该 Service 的 clusterIP(是虚拟 IP) 和 Port 的请求,并重定向到代理端口,代理端口再代理请求到后端Pod。
默认情况下,用户空间模式下的 kube-proxy 通过轮询算法选择后端。
iptables 代理模式
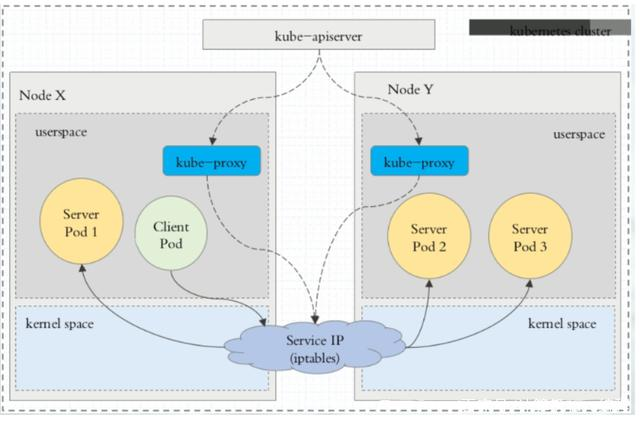
iptables 模式,kube-proxy 会监视 Kubernetes 控制节点对 Service 对象和 Endpoints 对象的添加和移除。对每个 Service,它会配置 iptables 规则,从而捕获到达该 Service 的 clusterIP 和端口的请求,进而将请求重定向到 Service 的一组后端中的某个 Pod 上面。对于每个 Endpoints 对象,它也会配置 iptables 规则,这个规则会选择一个后端组合。
默认的策略:kube-proxy 在 iptables 模式下随机选择一个后端
使用 iptables 处理流量具有较低的系统开销,因为流量是有 Linux netfilter 处理,而无需再用户空间和内核空间之间切换。
如果 kube-proxy 在 iptables 模式下运行,并且所选的第一个 Pod 没有响应,则连接失败。 这与用户空间模式不同:在这种情况下,kube-proxy 将检测到与第一个 Pod 的连接已失败,并会自动使用其它后端 Pod 重试。
可以使用 Pod 就绪探测器验证后端 Pod 可以正常工作,以便 iptables 模式下的 kube-proxy 仅看到测试正常的后端,这样做意味着避免将流量通过 kube-proxy 发送到已知已失败的 Pod 
ipvs 代理模式

在 ipvs 模式下,kube-proxy 监视 Kubernetes 服务和端点,调用netlink接口相应地创建 IPVS 规则,并定期将 IPVS 规则与 Kubernetes 服务和端点同步。该控制循环可确保 IPVS 状态与所需状态匹配。访问服务时, IPVS 将流量定向到后端 Pod 之一。
IPVS 代理模式基于类似于 iptables 模式的 netfilter 挂钩函数,但是使用哈希表 作为基础数据结构,并且在 内核空间 中工作。这意味着,与 iptables 模式下的 kube-proxy 相比,IPVS 模式下的 kube-proxy 重定向通信的延迟要短,并且在同步代理规则时具有更好的性能。与其它代理模式相比,IPVS 模式还支持更高的网络流量吞吐量。
IPVS 提供了不同的算法来转发平衡后端 Pod的流量。
rr(Round-Robin): 轮询算法lc(Least Connection): 最少连接数算法,即打开连接数最少者优先dh: 目标地址哈希算法(Destination Hashing)sh: 源地址哈希算法(Source Hashing)sed: 最短预期延迟算法(Shortest Expected Delay)nq: 不排队调度算法(Never Queue)
说明: 需要在 IPVS 模式下运行 kube-proxy,必须在启动 kube-proxy 之前使 IPVS 在节点上可用 ,当 kube-proxy 以 IPVS 代理模式启动时,它将验证 IPVS 内核模块是否可用。如果未检测到 IPVS 内核模块,则 kube-proxy 将 退回到以 iptables 代理模式运行 
在以上的代理模型中,绑定到服务 IP 的流量:在客户端不了解 Kubernetes 或 服务或 Pod 的任何信息的情况下,将 Port 代理到合适的后端。
如果要确保每次都将来自特定客户端的连接传递到同一 Pod,则可以通过将 service.spec.sessionAffinity 设置为 ClientIP(默认值为 None),来基于客户端的 IP地址选择会话关联。
还可以通过适当设置 service.spec.sessionAffinityConfig.clientIP.timeoutSeconds 来设置最大会话停留时间。(默认值为 10800 秒,即 3小时)
Service 使用
ClusterIP
ClusterIP 主要在每个 node 节点使用 iptables,将发向 ClusterIP 对应端口的数据,转发到 kube-proxy 中,然后 kube-proxy 自己内部实现负载均衡,并可以查询到当前 service 下对应后端的 pod 的地址和端口,进而把数据转发给对应 pod 的地址和端口。 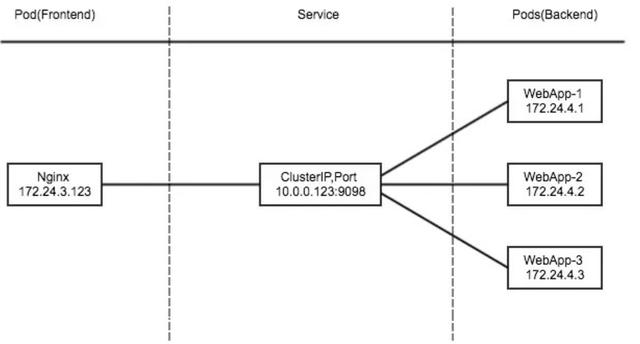
为了实现上述功能,主要通过 Kubernetes 的如下组件协同工作:
- apiserver: 用户通过 kubectl 命令向 apiserver 发送创建 service 命令,apiserver 接受到请求后,将数据存储到 etcd 中持久化;
- kube-proxy: Kubernetes 的每个 node 节点中都有一个叫做 kube-proxy 的进程,这个进程负责感知 service、pod的变化,并将变化的信息写入本地的 iptables 规则中;
- iptables: 使用 NAT 等技术将 virtualIP 的流量转发至对应的 endpoint 中
示例:创建 myapp-deploy.yaml
$ cat myapp-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deploy
labels:
app: myapp
spec:
replicas: 2
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: nginx
image: nginx:1.21
ports:
- containerPort: 80示例:创建 myapp-svc.yaml
$ cat myapp-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: myapp-svc
spec:
type: ClusterIP
selector:
app: myapp
ports:
- protocol: TCP
port: 80
targetPort: 80检查创建组件
$ kubectl apply -f myapp-deploy.yaml
$ kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
myapp-deploy-68ff95865b-hqf5t 1/1 Running 0 6m33s app=myapp,pod-template-hash=68ff95865b
myapp-deploy-68ff95865b-tmswb 1/1 Running 0 6m33s app=myapp,pod-template-hash=68ff95865b
$ kubectl apply -f myapp-svc.yaml
$ kubectl get svc myapp-svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
myapp-svc ClusterIP 192.168.217.143 <none> 80/TCP 4m41s
$ kubectl get ep
NAME ENDPOINTS AGE
kubernetes 10.0.20.13:6443 16d
my-service <none> 10d
myapp-svc 172.20.2.7:80,172.20.2.8:80 5m9s
#测试业务是否可以访问
$ curl -I 192.168.217.143
HTTP/1.1 200 OK
Server: nginx/1.21.4
Date: Wed, 05 Jan 2022 07:29:14 GMT
Content-Type: text/html
Content-Length: 615
Last-Modified: Tue, 02 Nov 2021 14:49:22 GMT
Connection: keep-alive
ETag: "61814ff2-267"
Accept-Ranges: bytesNodePort
NodePort 的原理是通过每一个节点上的的静态端口(NodePort)暴露 Service,同时自动创建 ClusterIP 类型的访问方式。在集群内部通过 (Port) 访问, 在集群外部通过 (NodePort) 访问。是 service 对公网暴露的一种方式 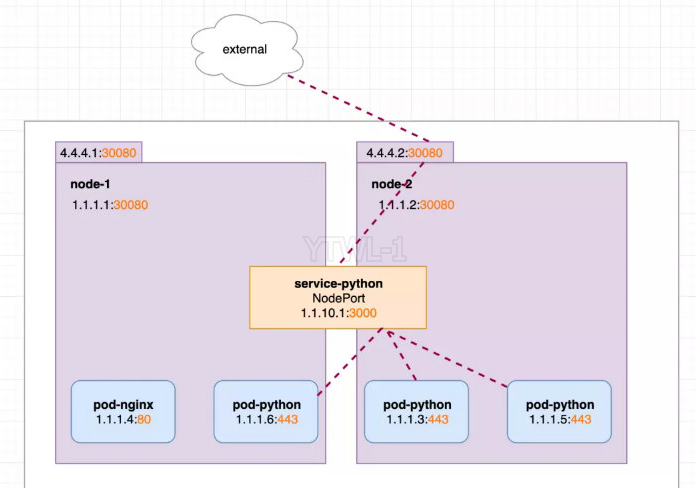
创建 Service信息
$ cat myapp-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: myapp-svc
spec:
type: NodePort
selector:
app: myapp
ports:
- protocol: TCP
port: 80
targetPort: 80
nodePort: 30002 # 如果不指定 NodePort 端口,系统会自动分配一个30000-32767范围内端口检查业务组件
$ kubectl apply -f myapp-svc.yaml
$ kubectl get svc myapp-svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
myapp-svc NodePort 192.168.217.143 <none> 80:30002/TCP 12m
# 集群内部访问
$ curl -I 192.168.217.143
HTTP/1.1 200 OK
Server: nginx/1.21.4
Date: Wed, 05 Jan 2022 07:36:45 GMT
Content-Type: text/html
Content-Length: 615
Last-Modified: Tue, 02 Nov 2021 14:49:22 GMT
Connection: keep-alive
ETag: "61814ff2-267"
Accept-Ranges: bytes
# 集群外部访问
$ curl -I 1.13.20.20:30002
HTTP/1.1 200 OK
Server: nginx/1.21.4
Date: Wed, 05 Jan 2022 07:37:48 GMT
Content-Type: text/html
Content-Length: 615
Last-Modified: Tue, 02 Nov 2021 14:49:22 GMT
Connection: keep-alive
ETag: "61814ff2-267"
Accept-Ranges: bytesLoadBalancer
通过云服务供应商(AWS、Azure、GCE 等)的负载均衡器在集群外部暴露 Service,同时自动创建 NodePort 和 ClusterIP 类型的访问方式。 如果我们希望有一个单独的 IP 地址,将请求分配给所有的外部节点IP(比如使用 round robin),我们就可以使用 LoadBalancer 服务,所以它是建立在 NodePort 服务之上的。 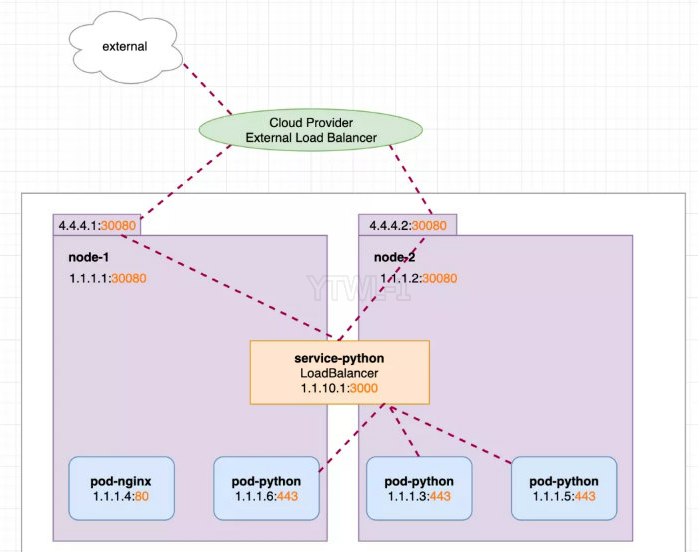
ExternalName
将 Service 映射到 externalName 指定的地址(例如:www.qiqios.cn) ,返回值是一个 CNAME 记录。不使用任何代理机制。ExternalName 类型的 Service 映射到一个外部的 DNS name,而不是一个 pod label selector。可通过 spec.externalName 字段指定外部 DNS name。
$ cat ex-svc.yaml
kind: Service
apiVersion: v1
metadata:
name: service-python
spec:
ports:
- port: 3000
protocol: TCP
targetPort: 443
type: ExternalName
externalName: www.qiqios.cn
# 查看集群DNS地址
$ kubectl get svc kube-dns -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 192.168.0.10 <none> 53/UDP,53/TCP,9153/TCP 18d
# 使用集群DNS解析 service-python
$ dig service-python.default.svc.qiqios.com @192.168.0.10
; <<>> DiG 9.11.3-1ubuntu1.15-Ubuntu <<>> service-python.default.svc.qiqios.com @192.168.0.10
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 53651
;; flags: qr aa rd; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
; COOKIE: f94c0420107f685f (echoed)
;; QUESTION SECTION:
;service-python.default.svc.qiqios.com. IN A
;; ANSWER SECTION:
service-python.default.svc.qiqios.com. 30 IN CNAME www.qiqios.cn.
www.qiqios.cn. 30 IN A 116.63.144.203
;; Query time: 20 msec
;; SERVER: 192.168.0.10#53(192.168.0.10)
;; WHEN: Fri Jan 07 15:27:39 CST 2022
;; MSG SIZE rcvd: 171
# 默认集群解析地址,可以登录pod查看
$ kubectl exec -it nginx-deployment-6fc77dcb7c-wgfvq -- sh
# cat /etc/resolv.conf
nameserver 192.168.0.10
search default.svc.qiqios.com svc.qiqios.com qiqios.com说明:ExternalName Service 是 Service 的特例,它没有 selector,当查询主机 service-python.default.svc.qiqios.com时,集群的 DNS服务将返回一个值 www.qiqios.cn 的 CNAME记录。访问这个服务的工作方式和其他的相同,唯一不同的是重定向发生在 DNS层,而且不会进行代理或转发。